颠覆性科技投资丨Figure AI大脑和World Labs空间智能模型的异同

5.4亿年前的寒武纪,生命史上发生了一场意义深远的“大爆发”。
这一演化奇迹的触发点,被许多生物学家归结为“眼睛”的出现——当原始生物第一次能够通过感知空间来捕猎和避障时,智能的演化便驶入了快车道。
如今,在人工智能领域,我们正处于类似的节点。
过去两年,大语言模型(LLM)让AI学会了像人类一样“说话”,但正如斯坦福大学教授李飞飞所言,这些模型本质上仍是“在黑暗中工作的文字匠人”:它们知识渊博却缺乏根基,能言善辩却无从体验。
AI的下一个前沿,是让机器从虚拟的文本空间走向物理的三维世界。
在这场通往通用人工智能(AGI)的竞赛中,两家公司成为了最受瞩目的标杆:
一家是李飞飞创立的World Labs,致力于构建具备“空间智能”的世界模型;
另一家是Figure AI,旨在通过垂直整合打造最先进的具身智能机器人大脑。
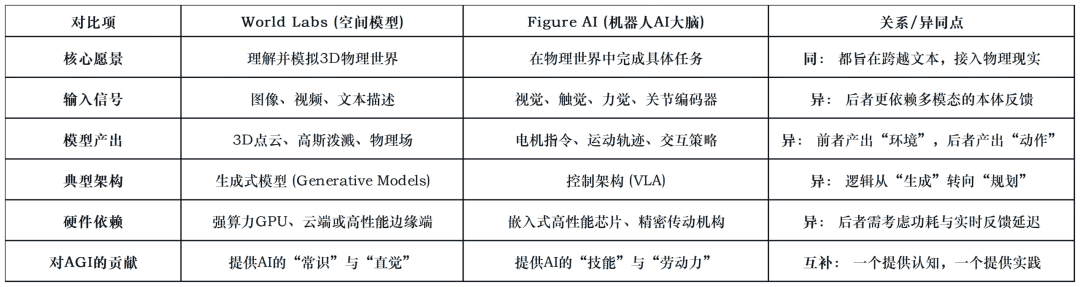
两者都指向物理世界,但它们在底层逻辑、应用前景、技术路径上有许多的区别和联系。
01 World Labs——为AI打造“三维模拟器”
LLM是在理解人类的语言,World Labs的目标是让AI学习物理世界如何运行。
1、空间智能:从“看见”到“推理”
World Labs的核心关键词是“空间智能”(Spatial Intelligence)。
在李飞飞看来,空间智能不仅仅是视觉识别,它包含三大支柱:
想象力:像故事讲述者一样创造连贯的3D环境。
敏捷性:像急救人员一样在复杂空间中导航。
严谨性:像科学家一样推演物体之间的物理关系。
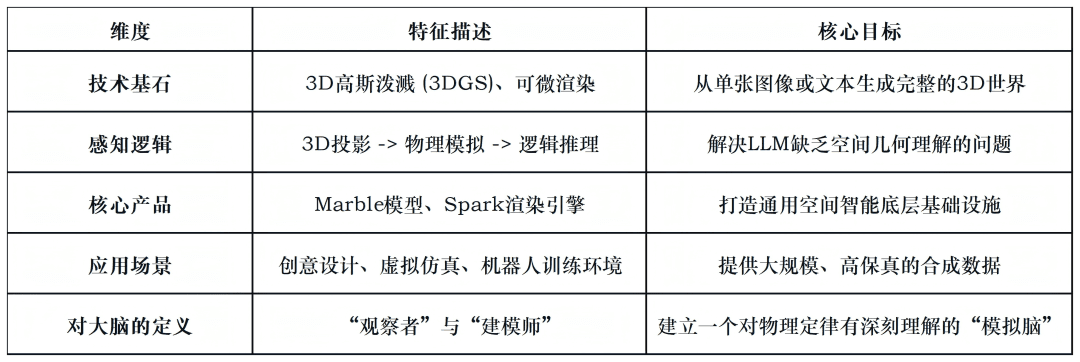
World Labs推出的Marble模型,代表了其对“世界模型”的初步实践。
它不再是简单地生成像素(如OpenAI的Sora),而是生成可交互、符合物理定律的3D空间。
2、技术杀手锏:3DGS与Spark 2.0
为了让这些空间在任何设备上都能流畅运行,World Labs选择了3D高斯泼溅(3D Gaussian Splatting, 3DGS)技术。
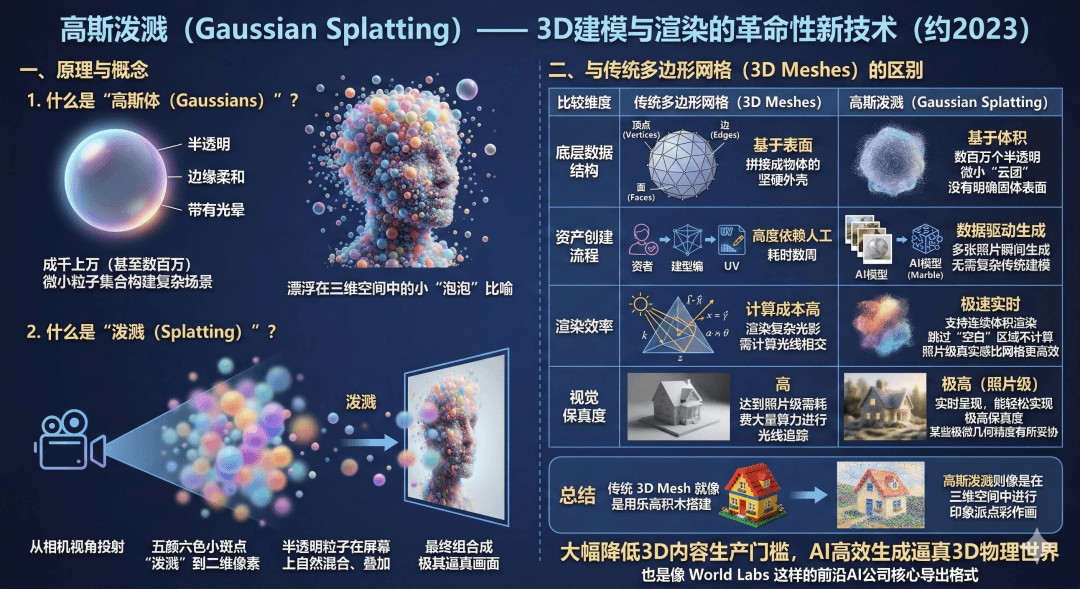
最近发布的Spark 2.0渲染引擎,能在浏览器中流式传输并渲染超过1亿个高斯点。
这意味着,未来的AI大脑可以在极短时间内“脑补”出一个高精度、可操作的三维场景。
图表1:World Labs“空间模型”核心特征简表
02 Figure AI——赋能“肉身”的实时决策脑
如果说World Labs是在建造“矩阵”(Matrix),那么Figure AI则是在打磨进入矩阵的“代理人”(Agent)。
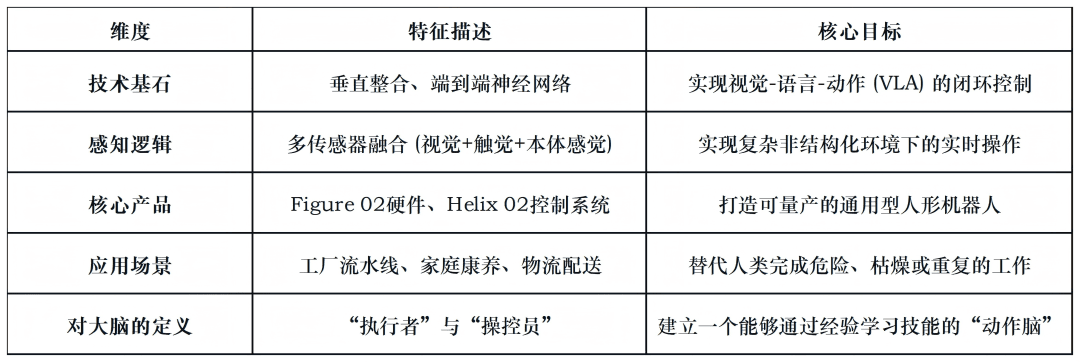
1、从OpenAI“分家”:走向垂直整合
Figure AI最初与OpenAI有过紧密合作(Figure 01曾展示过由OpenAI驱动的语音交互能力)。
但在2025年初,创始人Brett Adcock果断宣布终止与OpenAI的合作,转向开发自己的自研大模型。
原因很直接:通用的、跑在云端的大模型无法满足机器人对实时性(Real-time)和物理交互(Tactile Sensing)的严苛要求。
机器人的大脑必须与身体深度绑定。
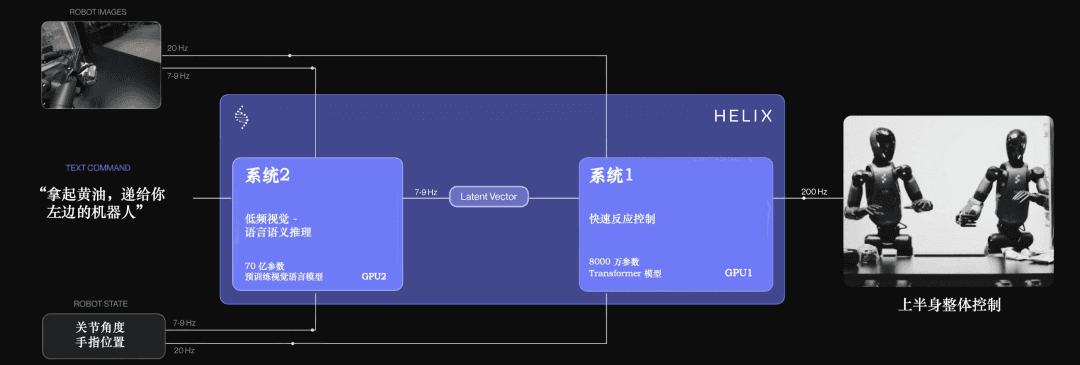
2、Helix 02系统:全身自主性的关键
Figure AI最新发布的Helix 02控制系统,展示了其对“机器人AI大脑”的理解。
该系统是一个统一的神经网络,它不仅处理视觉输入(通过手掌相机和躯干相机),还处理触觉反馈。
Helix 02实现了感知、规划和控制的“端到端”融合,使得Figure 03机器人能够像人类一样,一边走路一边整理客厅,而不需要在不同动作间进行生硬的逻辑切换。
图表2:Figure AI“机器人大脑”核心特征简表
03 深度对比——“世界”与“个体”的逻辑分野
两家公司的切入点不同,World Labs关注的是“世界是如何组成的”,而Figure AI关注的是“我如何在世界中行动”。
异同点剖析:
数据的本质不同
World Labs的数据主要是多维的几何数据和物理模拟参数,目的是为了“复现”现实。
Figure AI的数据更多是“轨迹数据”(Trajectory Data),即在特定环境下,关节应该如何受力、手指如何抓取的动作序列。
对LLM的态度
World Labs将LLM视为一种接口(3D as Code),用文字作为指令来驱动3D世界的生成。
Figure AI则在努力让LLM瘦身并“具身化”,使其不仅懂语义,更要懂“力矩”和“重心”。
预测能力的差异
World Labs预测的是“未来的场景状态”(例如:球踢出去后,场景会变成什么样)。
Figure AI预测的是“下一步的动作”(例如:为了接住球,我的手应该放在哪里)。
表3:World Labs空间模型 vs. Figure AI机器人大脑(异同点对比)
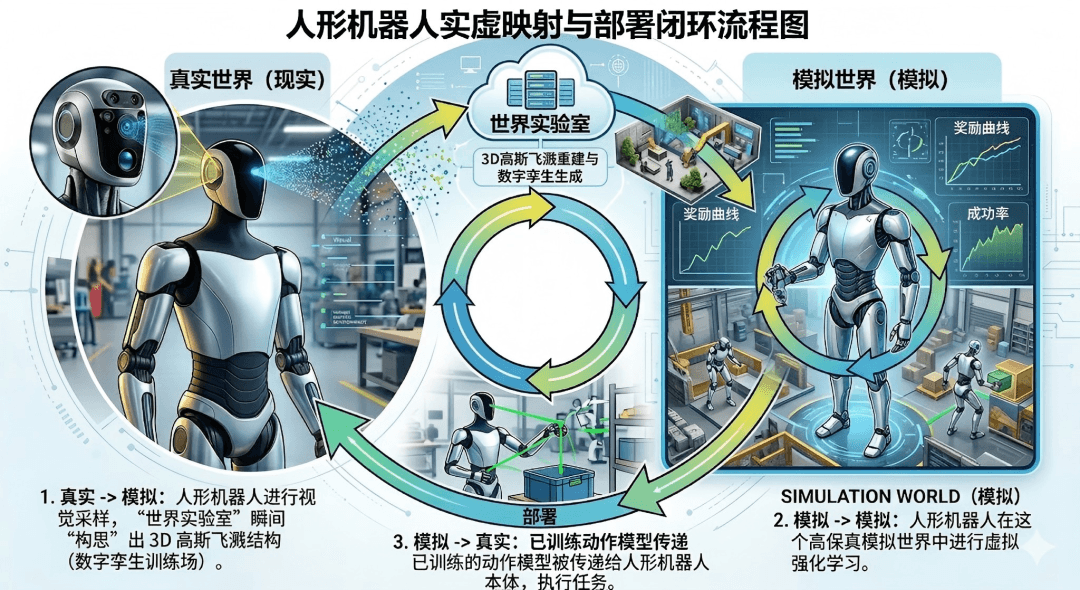
04 前瞻预期——两条路径的交汇点
World Labs和Figure AI技术的终局大概率是合流。
我们可以预见,在不久的将来,Figure AI旗下的机器人或许会内置World Labs的空间智能模块。
当机器人进入一个从未见过的房间时,它的“空间脑”会瞬间通过极少量的视觉采样,脑补出整个房间的3DGS结构(即World Labs擅长的事),然后它的“动作脑”再基于这个精确的三维地图进行路径规划和物体抓取(即Figure AI擅长的事)。
Real-to-Sim-to-Real(现实-模拟-现实)将成为闭环:
Real->Sim:机器人感知现实,World Labs将其转化为高精度模拟世界。
Sim->Sim:机器人在模拟世界中进行成千上万次的虚拟强化学习。
Sim->Real:训练好的动作模型,下发到真实的机器人肉身中执行任务。
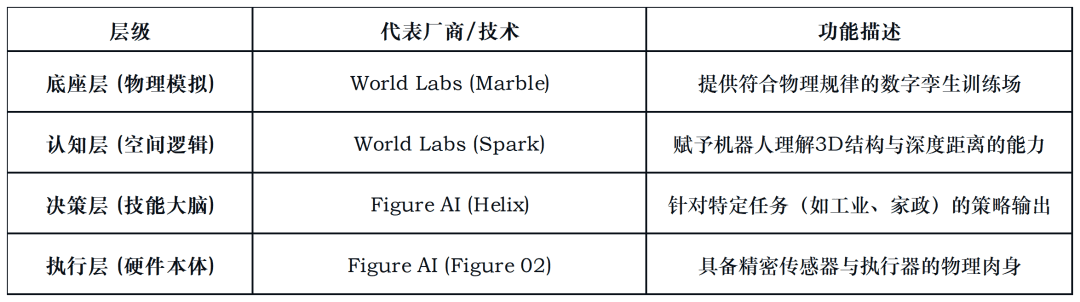
图表4:未来具身智能产业链分工构想
05 结语:寒武纪大爆发的现代版
人类智能之所以能够产生,是因为我们的祖先在三维世界中不断与物体碰撞、互动、学习。
现在的AI,正经历着同样的进化路径。
World Labs正在为AI点亮“眼睛”,让它看清世界的深度;而Figure AI正在为AI铸造“手脚”,让它在磨砺中产生肌肉记忆。
正如李飞飞在她的万字长文中提到的:“我们将建造与物理世界如此契合的机器,使其能成为我们应对重大挑战的真正伙伴。”
这场变革才刚刚开始,从“文字匠人”到“世界大师”的跨越,将是未来十年AI领域最激动人心的故事。
当我们再次感叹具身智能机器人的灵巧时,请记住,那不仅是硬件的胜利,更是人类第一次成功地将物理世界的逻辑,编码进了一串串字符与权重之中。


